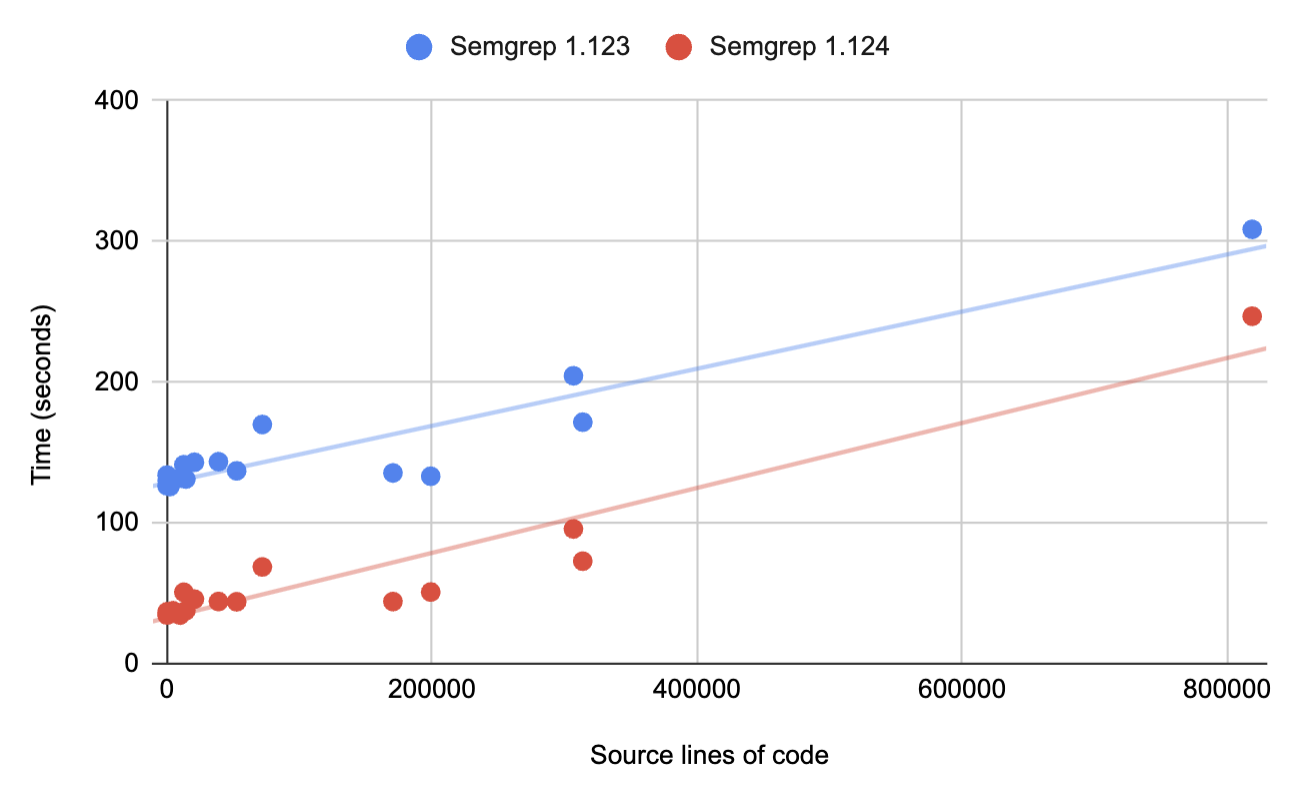
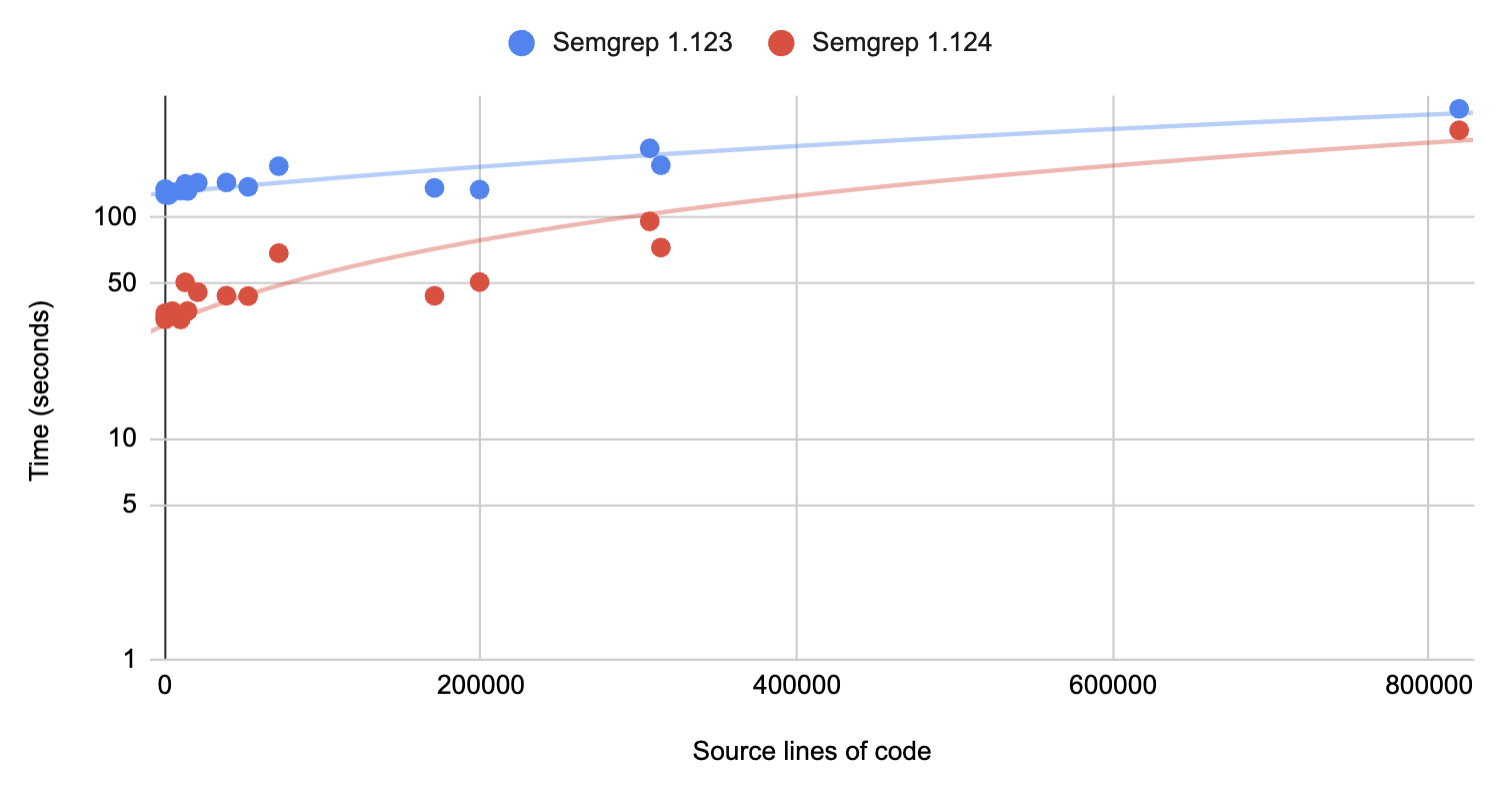
With each release, we ship new improvements to source-code scanning features, language coverage, framework support, integration options, and better security rules. We've had over twenty releases this calendar year, and the latest update (v1.124) includes performance improvements that can make Semgrep up to 3x faster than before under specific conditions.
We prioritize speed, not only as a general feature, but as a prerequisite to achieving our mission. If static analysis slows down development, teams won't adopt it. If it isn't adopted, vulnerabilities don't get caught. That's what is important and why Semgrep is the preferred solution for security researchers, pentesters, consultants, application security engineers, open-source developers, and hobbyists alike.
This post dives into the (modest) performance improvement with additional context on which users will benefit. Semgrep Community Edition is licensed under the open-source LGPL 2.1. We appreciate not only customer feedback but open-source community contributions as well so that all can benefit.
Semgrep CE Releases a 3X Performance Improvement
Recent community reports suggested that Semgrep had room for improvement in rule-loading speed–particularly when using many small rule files. This prompted a closer look.
How Rule Loading Works with Semgrep
Rules define the semantic patterns for identifying security vulnerabilities. To provide customization for all types of users, there are multiple methods to pull in rules.
Single rule files:
--config=/path/to/ruleset.ymlMultiple rule files:
--config=/path/to/ruleset1.yml –config=/path/to/ruleset2.ymlDirectory of rules:
--config=/path/to/rule-dir/Fetched from the registry:
--config=autoCurated from a rule set:
--config=RULESET_ID
Each method has different performance characteristics when loading rules.We test across these permutations, often prioritizing the most common strategies, while ensuring generalizability.
Thanks to community feedback, we confirmed a bottleneck. Rule validation was single-threaded and I/O bound when processing a directory of many rules. We recommend using --config=auto which downloads a single file so this edge case doesn't exhibit itself very often. While the usage pattern is uncommon, those who do could see startup time reductions of up to 90 seconds. For small repositories, that can be a sizable gain (3x on average) and may help enable quick iterations during local development.